LLMs : The Next Frontier in AI


Introduction to LLM: A brief overview of what LLMs are and why they matter in today's AI-driven world. 🤖
Imagine a world where machines understand and generate human language with the same proficiency as humans. This is the realm of Large Language Models, a groundbreaking innovation in artificial intelligence.
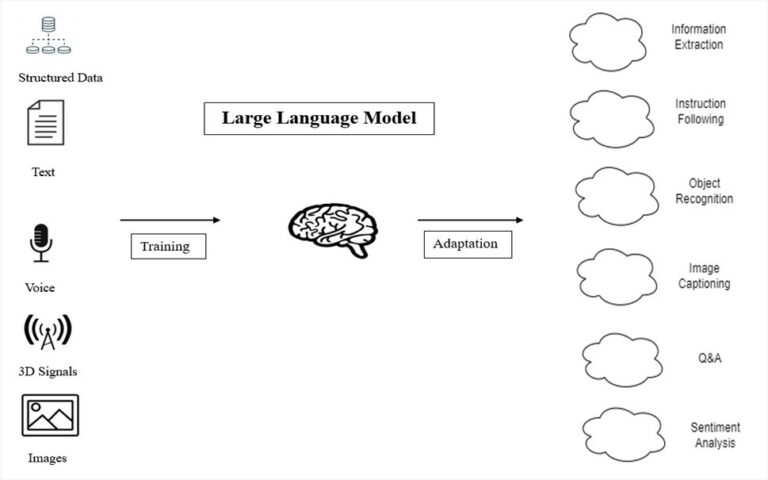
Large language models, also known as LLMs, are advanced artificial intelligence systems designed to understand and generate human language. They are trained on vast amounts of text data, allowing them to learn patterns, vocabulary, and syntax to generate coherent and meaningful text. These models continue to reshape the landscape of AI and Natural Language Processing (NLP). It’s important to stay updated on their abilities, difficulties, and possible opportunities.
They are trained on massive datasets of text and code, and they can be used for a variety of tasks, such as:
- Question answering: Answer your questions in an informative way, even if they are open-ended, challenging, or strange.
- Text generation: Creating different creative text formats, like poems, code, scripts, musical pieces, emails, letters, etc.
- Text Summarization: Creating a concise and informative summary of a text.
- Text Translation: Translating text from one language to another.
- Code generation: Writing code in a variety of programming languages.
- Data analysis: Analyzing data and identifying patterns.
- Creative writing: Writing different kinds of creative content, such as poems, stories, and scripts.
Key Considerations :
Technical Factors in Choosing a LLM :
1. Number of Parameters: The number of parameters in a model can influence its capacity and performance. Larger models with more parameters often have the potential to capture more complex patterns and achieve higher accuracy. However, larger models also require more computational resources for training and inference.
2. Size of Context Window: The context window refers to the amount of text or context that the model considers when generating responses or predictions. Models with larger context windows have a broader understanding of the context, which can be advantageous for generating more contextually relevant outputs. However, larger context windows can also increase computational requirements and inference time.
3. Training Type: Different models can be trained using various methods, such as supervised learning, unsupervised learning, or self-supervised learning. The training type can impact the model’s capabilities and generalization across different tasks. Understanding the training methodology and evaluating its suitability for specific use cases is important.
4. Inference Speed: Inference speed is a crucial factor, especially in real-time or latency sensitive applications. Faster inference speeds allow for more responsive systems and better user experiences. Models with smaller architectures or optimized implementations tend to have faster inference times.
5. Cost: The cost of using a particular LLM includes considerations such as licensing fees, computational resources required for training and inference, and ongoing maintenance costs. Enterprises should evaluate the cost implications and ensure that the chosen LLM aligns with their budget and cost expectations.
6. Fine-tunability: The ability to fine-tune the model to adapt it to specific use cases is valuable. Enterprises should consider the level of fine-tuning flexibility and the availability of resources and documentation for this process. Some models may offer more extensive fine-tuning capabilities than others.
7. Data Security: Data security is of paramount importance when working with LLMs. Enterprises should assess the data security practices of the provider, including encryption methods, access controls, and compliance with privacy regulations. Protecting sensitive data and ensuring secure handling and storage is crucial.
From MLOps to LLMOps:
API-based generative models come with their unique challenges, thus requiring a new framework called LLMOps. LLMOps is an emerging field that draws from MLOps and DevOps and is focused on managing the entire lifecycle of large language models, for robust, reliable, and efficient integration of large language models in the enterprise.
LLMOps and MLOps are related but distinct concepts in the domain of artificial intelligence and machine learning.
LLMops (Large Language Model Operations) :
- LLMOps is the management of the entire lifecycle of large language models and LLM applications through the application of MLOps principles.
- LLMops focuses on the operational aspects of deploying, managing, and maintaining large language models (LLMs), such as GPT (Generative Pre-trained Transformer) models developed by OpenAI.
- It involves tasks such as model training, fine-tuning, inference deployment, monitoring, and scalability considerations specific to LLMs.
- LLMops teams typically deal with challenges related to computational resources, model versioning, data privacy, bias mitigation, and ethical use of LLMs in real-world applications.
- Examples of LLMops tools and platforms include OpenAI’s GPT-3, Hugging Face’s Transformers library, and custom infrastructure for managing LLMs in production environments.
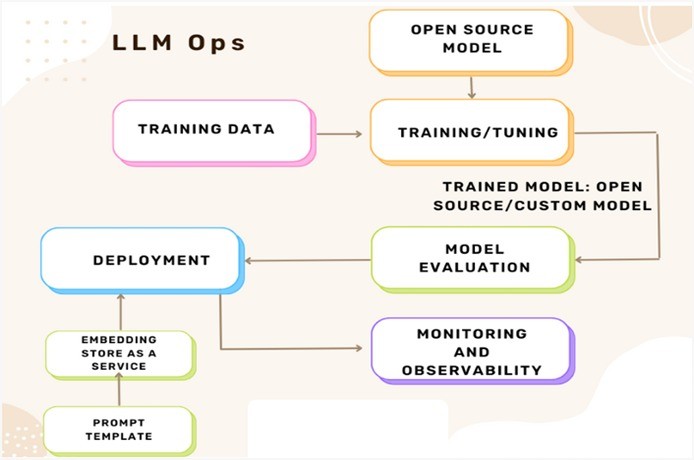
MLOps (Machine Learning Operations) :
- MLOps focuses on the end-to-end operationalization of machine learning models across the entire lifecycle, from development to deployment and beyond.
- It encompasses practices, tools, and methodologies for automating and streamlining ML workflows, including data ingestion, feature engineering, model training, evaluation, deployment, monitoring, and maintenance.
- MLOps aims to address challenges such as reproducibility, collaboration, model drift detection, model explainability, and continuous integration/continuous deployment (CI/CD) for ML systems.
- Examples of MLOps tools and platforms include MLflow, Kubeflow, TensorFlow Extended (TFX), Azure ML, and AWS SageMaker, which provide capabilities for managing ML pipelines, versioning models, and orchestrating deployments.
Key Challenges in LLMOps :
1. Computational Resources: Extensive language model integration for training and optimization requires significant computational resources, including specialized hardware like GPUs. Access to dedicated computational resources is crucial for both training and deploying LLMs. Additionally, optimizing inference costs highlights the importance of techniques such as model compression and distillation.
2. Transfer Learning: Many large language models (LLMs) differ from conventional machine learning models because they fine-tune a foundation model using new data to improve performance in specific areas. This fine-tuning helps achieve advanced functionality for specific applications while using less data and computational resources.
3. Human Feedback: Training LLMs has seen notable improvement through RLHF. End-user input plays a crucial role in evaluating LLM effectiveness due to the open-ended nature of LLM tasks. Integrating this feedback loop into LLMOps pipelines streamlines evaluation and provides valuable data for potential future fine-tuning.
4. Hyperparameter Tuning: In contrast to conventional machine learning, large language models (LLMs) require broader considerations, such as cost-efficiency and reduced computational requirements. Factors like batch sizes and learning rates have a significant impact on training speed and costs, necessitating unique optimization strategies compared to traditional machine learning approaches.
5. Performance Metrics: The performance metrics used for traditional machine learning models differ significantly from those used for large language models. Evaluation of large language models relies on metrics like BLEU and ROUGE, which require careful implementation.
6. Prompt Engineering: The accuracy and trustworthiness of instruction-following language models (LLMs) depend on well-crafted prompt templates. Careful prompt engineering reduces the chances of the model producing incorrect content, inserting irrelevant prompts, revealing sensitive data unintentionally, and causing security issues.
7. Constructing LLM Chains or Pipelines: The construction of LLM pipelines, facilitated by tools like LangChain or LlamaIndex, empowers the seamless connection of multiple LLM calls and interactions with external systems such as vector databases or web searches. These pipelines facilitate complex tasks, including knowledge base Q&A and responding to user queries based on a corpus of documents.
Challenges Faced By the Market Segment :
1. Cost of Labeled Data: The considerable need for labeled data poses a significant challenge in the fine-tuning of large language models. Acquiring sufficient labeled data to train these models can be an expensive endeavor. The costs associated with data collection, annotation, and curation can be prohibitive for certain businesses, hindering their ability to engage in effective fine-tuning.
2. Time-Intensive Fine-Tuning Process: The process of fine-tuning large language models, despite access to robust computational resources, can be time-consuming. This temporal aspect presents challenges to businesses seeking to swiftly adapt their models to evolving market conditions. The prolonged fine-tuning process can potentially limit a company’s agility in responding to dynamic demands.
3. Risk of Overfitting: One pertinent challenge in fine-tuning is the risk of overfitting. As the model becomes excessively tailored to the training data, its capacity to generalize to new, unseen data might be compromised. This overfitting phenomenon, if not managed effectively, can lead to subpar performance when the model encounters data beyond its training scope.
4. Lack of Expertise: The intricate nature of fine-tuning large language models necessitates specialized expertise in machine learning and natural language processing. Securing professionals with the requisite skills can be a challenging endeavor, both in terms of identification and affordability. This scarcity of expertise can impact a company’s ability to fine-tune models optimally.
LLMOps : Everything You Need to Know to Manage LLMs & Best Practices for tuning LLMs
Fine Tuning Large Language Models :
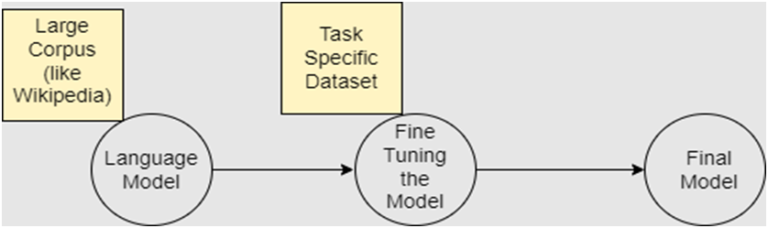
1. Task-specific Adaptation: While pre-trained models like GPT-3 possess a general understanding of language, they might not be directly suitable for specific tasks or domains. Fine-tuning allows the model to specialize in a particular task, making it more accurate and efficient.
2. Domain Expertise: Fine-tuning helps the model gain domain-specific knowledge that might not be present in the general pre-training data. For instance, a model intended for medical text might need to understand medical jargon and concepts, which it can learn through fine-tuning on medical text data.
3. Data Scarcity: In some cases, there might not be enough task-specific data to train a large model from scratch. Fine-tuning can leverage the knowledge encoded in the pre-trained model while adapting to the specific task using a smaller amount of task-specific data.
4. Better Resource Utilization: Fine-tuning is computationally less intensive compared to training a model from scratch. Utilizing pre-trained models and fine-tuning them is more resourc eefficient and faster than training a model from the ground up.
5. Faster Deployment: Pre-trained models have already learned grammar, syntax, and some level of semantics from a massive amount of text. Fine-tuning allows for quicker deployment of models that can understand and generate human-like text, saving time and resources.
6. Mitigating Biases: Pre-trained models can inadvertently contain biases present in their training data. Fine-tuning provides an opportunity to address and mitigate these biases by focusing on fairness and inclusivity during the fine-tuning process.
7. Control and Customization: Fine-tuning allows developers to have more control over the model’s behavior and output. By fine-tuning, you can shape the model’s responses to align with specific guidelines, tones, or preferences.
8. Improved Performance: Fine-tuning can lead to significant improvements in performance for specific tasks. The model can learn to generate more contextually relevant and accurate responses.

There are many tools available for fine-tuning large language models. Some of the most popular ones include:
1. Hugging Face Transformers: This is a popular open-source library that provides easy access to pre-trained language models and utilities for fine-tuning. It supports a wide range of tasks, including text classification, question answering, and summarization.
2. PyTorch Lightning: This is a framework for training deep learning models that is designed to be easy to use and efficient. It includes a number of features that are useful for fine-tuning large language models, such as distributed training and hyperparameter optimization.
3. DeepSpeed: This is a library that can accelerate the training and inference of large language models by using a number of techniques, such as mixed precision and distributed training.
4. Google AI Platform: This is a cloud platform that provides a number of tools for training and deploying machine learning models. It includes a managed instance of TPUs, which are specialized hardware accelerators for machine learning.
5. Amazon SageMaker: This is another cloud platform that provides tools for training and deploying machine learning models. It also includes a managed instance of TPUs.
6. LMFlow: An Extensible Toolkit for Finetuning and Inference of Large Foundation Models.
Best Practices for Tuning LLMs :
1. Define Clear Objectives :
Example: Suppose you’re fine-tuning a model to perform sentiment analysis on movie reviews.
Task-Specific Goals: The model should accurately classify reviews as positive, negative, or neutral.
Performance Metrics: Use metrics like accuracy, precision, recall, and F1 score to evaluate performance.
2. Data Preparation :
Example: For training a chatbot, ensure the data is high-quality and diverse.
High-Quality Data: Use a clean and annotated dataset, like customer service conversations.
Data Augmentation: Generate additional training examples by paraphrasing sentences or using synonyms.
Balanced Dataset: Ensure the dataset has an equal number of positive and negative samples to avoid bias.
3. Preprocessing :
Example: Preparing text data for training a text summarization model.
Text Normalization: Convert all text to lowercase, remove punctuation, and handle contractions (e.g., “don’t” to “do not”).
Tokenization: Use subword tokenization (like BPE) that aligns with models like GPT-3.
Padding and Truncation: Pad or truncate sentences to a fixed length to ensure uniform input size.
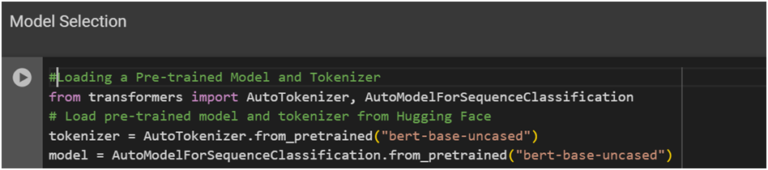
4. Model Selection and Initialization :
Example: Fine-tuning BERT for a question-answering task.
Pre-trained Models: Start with a pre-trained BERT model available on Hugging Face.
Fine-Tuning: Fine-tune BERT on a specific dataset like SQuAD (Stanford Question Answering Dataset).
Code Snippet :
5. Hyperparameter Tuning :
Example: Fine-tuning hyperparameters for a text classification task.
Learning Rate: Experiment with different learning rates (e.g., 1e-5, 3e-5, 5e-5) and choose the one that provides the best validation performance.
Batch Size: Test various batch sizes (e.g., 16, 32) to balance training speed and model stability.
Epochs: Start with a smaller number of epochs (e.g., 3-5) to avoid overfitting, and monitoring validation performance.
Code Snippet :

6. Regularization Techniques :
Example: Preventing overfitting in a named entity recognition task.
Dropout: Apply dropout with a rate of 0.1 to the transformer layers to regularize the model.
Early Stopping: Implement early stopping if the validation loss does not decrease for several epochs.
Weight Decay: Use weight decay (e.g., 0.01) to penalize large weights.
Code Snippet :

7. Evaluation and Validation :
Example: Evaluating a language model for machine translation.
Validation Set: Use a separate validation set from the training data to tune hyperparameters.
Cross-Validation: Perform k-fold cross-validation to ensure the model’s robustness.
Evaluation Metrics: Use BLEU score to evaluate the quality of translations.
Code Snippet :

8. Fine-Tuning Strategies :
Example: Adapting a pre-trained GPT model for text generation in a specific domain.
Layer Freezing: Freeze lower layers initially and fine-tune only the top layers to retain general language understanding.
Gradual Unfreezing: Gradually unfreeze layers during training to allow the model to adapt better to the new task.
Learning Rate Schedulers: Use a learning rate scheduler like cosine annealing to adjust the learning rate dynamically.
Code Snippet :


9. Monitoring and Logging :
Example: Tracking experiments while fine-tuning a conversational AI model.
Track Experiments: Use tools like Weights & Biases to log hyperparameters, training metrics, and model checkpoints.
Logging Metrics: Log loss, accuracy, and other relevant metrics to analyze model performance over time.
10. Post-Processing and Deployment :
Example: Optimizing a sentiment analysis model for deployment on mobile devices.
Model Quantization: Apply quantization techniques to reduce model size without significantly impacting performance.
Pruning: Remove redundant weights to speed up inference.
Deployment Considerations: Optimize the model for low-latency environments, ensuring it meets the performance requirements of the deployment platform.
11. Ethical Considerations :
Example: Ensuring fairness in a recommendation system.
Bias Mitigation: Analyze the model’s recommendations for bias and implement techniques to mitigate it, such as re-sampling or re-weighting data.
Transparency: Provide explanations for the model’s recommendations to ensure transparency.
Privacy: Comply with data privacy regulations like GDPR by anonymizing sensitive data.
Conclusion :
At IOSCAPE, we are leveraging the power of Large Language Models (LLMs) to revolutionize predictive maintenance within the Internet of Things (IoT) ecosystem. By enhancing data processing, user interaction, and decision-making. LLMs can analyze data from IoT sensors to predict equipment failures. They can generate easy-to-understand maintenance reports in natural language and schedule maintenance before issues arise. When an LLM detects a potential problem, it can automatically generate alerts and provide actionable recommendations in plain language. LLMs can continuously learn from new data, improving their predictive accuracy.